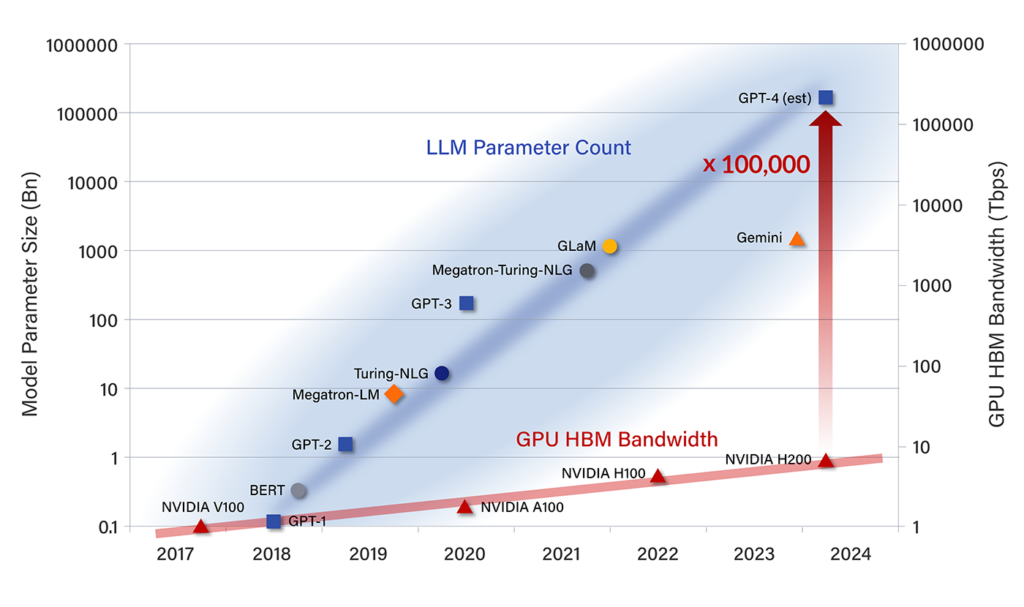
최근 몇 년 동안 AI 분야에서는 대규모 언어 모델(LLM)의 연구가 눈에 띌 정도로 활발하게 이루어지고 있습니다. 동시에 성능 또한 엄청난 성장을 하고 있습니다. 그리고 언어 모델의 크기에 비례하여 성능이 더 좋아지는 것이 다양한 연구들에서 확인이 됐습니다. 그래서 성능을 올리기 위해 언어 모델의 크기를 계속 키워 나갔지만… 부작용이 생겨버렸습니다. 바로 언어모델의 크기가 커지면서 배포(deployment)가 점점 어려워지고, 많은 전력량을 사용하게 되면서 이로 인한 환경 및 경제적 영향에 대한 우려가 발생한 것인데요.
LLM parameter count growth
그러면 우리는 이런 문제들 때문에 성능을 포기하고 크기가 작은 언어모델을 사용해야 할까요? 아니죠. 인간은 언제나 그렇듯 방법을 찾아 냅니다. 바로 양자화 입니다.
양자화(quantization)가 뭐에요?
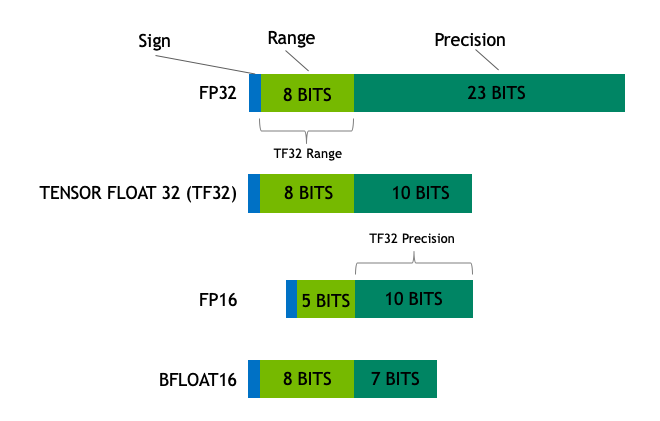
양자화의 전단계로, 언어 모델을 학습 시킵니다. 그리고 학습된 모델의 파라미터를 표현하는 비트의 수를 극단적으로 줄인 모델을 생성하는 것이 양자화 입니다. 양자화를 대중적으로 사용하기 전부터 이미 모델의 크기를 줄이려는 시도는 있어왔습니다. FP32, fp16, bf16과 같은 자료형을 보신적이 있으실 겁니다.
FP32, TF32, FP16, BF16
FP32가 뭐였죠?
FP32는 가장 표준이 되는 IEEE 32비트 부동소수점을 나타내는데요, 1개의 부호비트, 8개의 지수부, 23개의 가수부로 이루어져 있습니다. 파라미터를 표현할 때 FP32를 사용한다면, 파라미터 하나 당 4Byte를 차지하게 되죠. 그럼 만약 저희에게 친근한 LlaMa2 7B모델을 FP32로 표현하면 총 얼마의 메모리가 필요할까요? 7*10^9*4Byte = 28GB의 크기가 필요하겠죠? 현재 일반 사용자용으로 제공되는 그래픽카드 중 가장 성능이 좋고 VRAM이 많은 모델인 RTX4090도 24GB의 VRAM을 가지고 있습니다. FP32를 사용한다면 일반 사용자들은 7B모델도 사용을 못하겠군요…
FP16, BF16의 차이는 뭐에요?
그럼 FP16이나 BF16을 살펴보겠습니다. 이 둘은 공통적으로 16비트이지만 FP16은 지수부가 5비트, 가수부가 10비트를 가지고 있습니다. 지수부가 5비트 밖에 안되기 때문에 표현할 수 있는 수의 범위가 [6.10^10-5, 65504] 입니다. 하지만 기존 FP32[1.4*10-45, 1.7*10^38]에 비해 나타낼 수 있는 범위가 매우 좁아서 오버플로우나 언더플로우가 발생할 가능성이 매우 높습니다.
그래서 그 대안으로 나온것이 BF16인데요, 지수부를 8비트, 가수부를 7비트를 가져가서 FP32와 동일한 표현범위를 가져갈 수 있습니다. 다만 FP16에 비해 3bit의 정밀도를 잃기는 하지만요. 그러면 LlaMa2 7B모델을 BF16을 이용해 표현하면 얼마의 메모리가 필요할까요? 7*10^9*2Byte = 14GB가 필요하겠네요. 드디어 일반 사용자도 7B모델을 사용할 수 있게 되었습니다! 물론 비싼 그래픽카드를 가지고 있어야 하죠..
크기가 절반이면 성능도 절반이 되는거 아닌가요?
근데 파라미터당 크기를 4Byte에서 2Byte로 절반이나 줄이다 보니 ‘어 이러면 언어모델의 성능도 절반으로 줄어들지 않을까?’ 하는 걱정이 드는데요. 실험적으로 full precision(FP32)을 사용한 모델과 half precision(FP16, BF16)을 사용한 모델이 거의 동일한 결과를 보이는 것을 확인했습니다. 언어모델 성능 걱정은 안해도 되겠군요!
더 줄여도 되는 거 아닌가요?
그러면 이제 슬슬 ‘어.. 더 줄여도 되는거 아닌가?’ 하는 생각이 들 때가 됐습니다. 안타깝게도 이런 방식으로는 정밀도가 낮아지면 추론 품질이 급격하게 떨어지게 됩니다.
그러면 크기를 더 못줄이나요?
8비트 양자화를 적용하는 이유는 추론 품질이 급격하게 떨어지는 문제를 해결하기 위함 입니다. 이 방법은 4분의 1의 정밀도를 사용하므로 모델 크기가 1/4 밖에 안되죠! 하지만 비트 수를 반으로 줄인다고 해서 양자화가 완료되는 것은 아닙니다.
양자화는 기본적으로 한 데이터 타입에서 다른 데이터 타입으로 변형되면서 반올림하는 방식으로 수행되는데요. 이 과정에서 정보 손실이 일어나게 되므로 half precision보다 성능이 떨어질 수 밖에 없습니다. 그래서 이 정보 손실을 최소화 하면서 모델의 크기도 최소화 하는 방향으로 연구가 계속 이루어지고 있습니다.
가장 일반적인 두 가지 8비트 양자화 기술은 영점 양자화 및 최대 절대값(absmax) 양자화입니다. 영점 양자화 및 최대 절대값 양자화는 부동 소수점 값을 int8(1바이트) 로 매핑합니다.
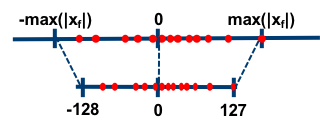
zero-point quantization
영점 양자화는 scaling을 통해서 최댓값을 127, 최소값을 -127로 만들고 반올림하여 양자화 하는 방법입니다. 최소값과 최대값의 평균이 0이 되게 만들죠. min-max scaling과 같다고 보면 됩니다.
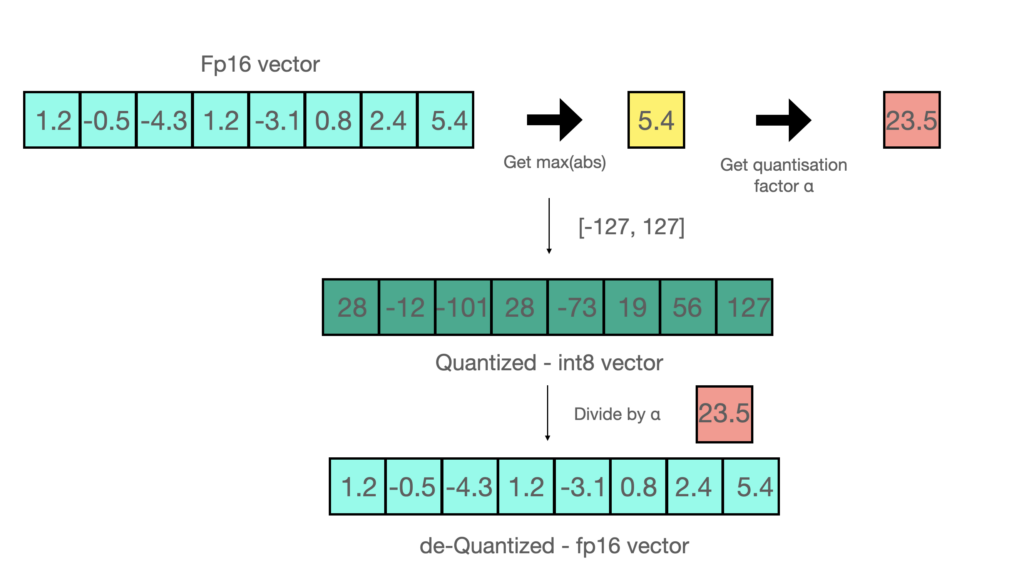
absmax quantization
최대 절대값 양자화는 모든 값을 최대값으로 나눈 뒤 127(int8의 경우)을 곱한 뒤 반올림하면 됩니다. 그림의 예시에서는 최대 절대값이 5.4 이므로 모든 값을 5.4로 나누고 127을 곱하면 되는데, 이때 계산을 한번에 편하게 하면 그냥 모든 수에 23.5(127/5.4)를 곱하면 되고, 이 값을 quantization factor라고 부릅니다. 나중에 이 값으로 나누어서 de-quantization을 하죠.
8비트 보다 더 줄이고 싶어요!
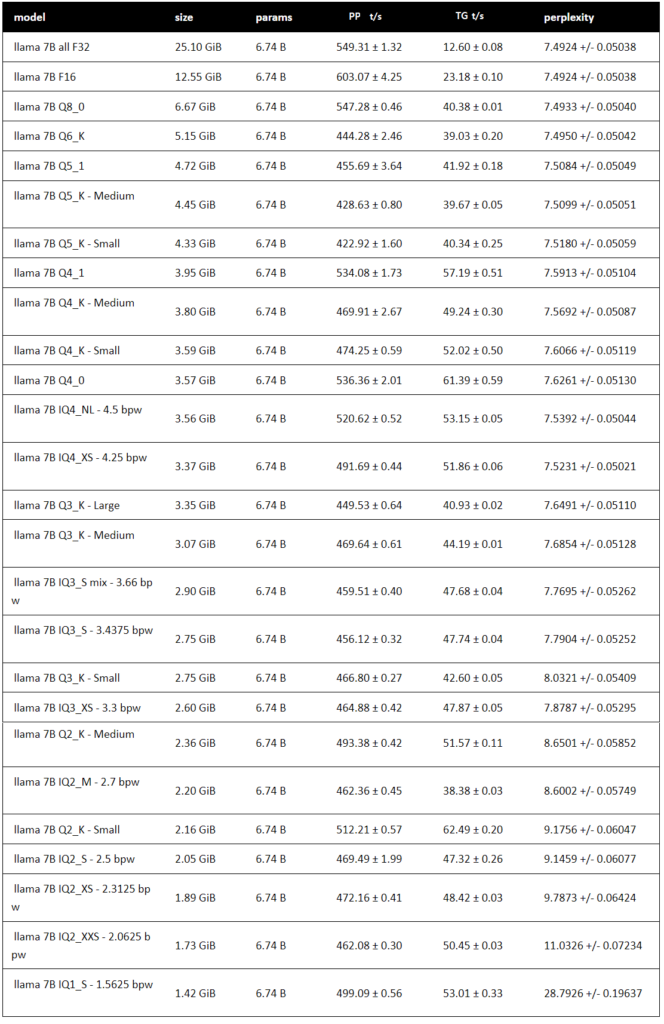
8비트 보다 더 낮게 양자화 하는 다양한 방법론들이 있습니다. 그 중에서 GPTQ, GGUF, AWQ가 대표적으로 사용되는 방법들입니다. 이 방법들에 대해서 설명하는 것은 양도 많고 이 글의 범위를 벗어 나기 때문에 설명은 제외하겠습니다. LlaMa2 7B 모델을 기준으로 다양한 bit와 다양한 옵션으로 양자화를 했을 때 FP16에 비해 성능이 얼마나 변하는지 표로 확인해 보시죠. 보통 언어 모델은 perplexity를 기준으로 성능 평가를 하게 되는데요, perplexity는 다음 단어를 예측할 때 몇 개의 단어 후보를 고려하는지를 의미합니다. perplexity가 높을 수록 다음 단어에 어떤게 와야할지 헷갈려한다는 뜻이기 때문에 모델이 성능이 좋지 않다고 볼 수 있습니다. 따라서 perplexity는 낮을 수록 성능이 좋은 지표입니다.
LlaMa2 7B perplexity according to quantized bits
위 표의 칼럼을 간단하게 설명드리겠습니다.
model
양자화 bit 및 양자화 방법론
size
양자화된 모델의 사이즈
params
llama2의 파라미터 크기 (6.74B로 고정)
PP t/s
Prompt Processing token/second, 초당 처리하는 입력 토큰 수
TG t/s
Token Generation token/second, 초당 생성하는 토큰 수
perplexity
모델 성능 지표, 값이 낮을 수록 좋음
다양한 크기로 양자화된 모델을 비교된 표를 살펴보면 전반적으로 양자화된 bits수가 적을 수록 perplexity가 올라가는 것을 볼 수 있습니다. 양자화를 극한으로 할 수록 정보의 손실이 많아지기 때문에 당연한 결과라고 보입니다. 특히 IQ4_XS-4.25bpw 모델을 보면 perplexity가 평균 7.5231인데 원래 모델 크기의 13%밖에 안되는 크기를 가지지만 perplexity가 원본 모델과 단 0.0307밖에 차이가 안납니다. 좋은 양자화 성능을 보여주죠.
1.58비트는 어디서 나온거에요?
만약 1bit까지 극한으로 양자화를 한다면 모델의 성능이 어떻게 될까요? 위의 perplexity표에도 1bit 양자화 모델이 있긴 하지만 성능을 보면 28.7의 값으로 성능이 매우 좋지 않은 것을 확인할 수 있습니다. 또한 작년에 이미 1 bit의 BitNet transformer[8]를 마이크로소프트에서 발표한 적이 있었는데, 역시 성능이 좋지 않았습니다.
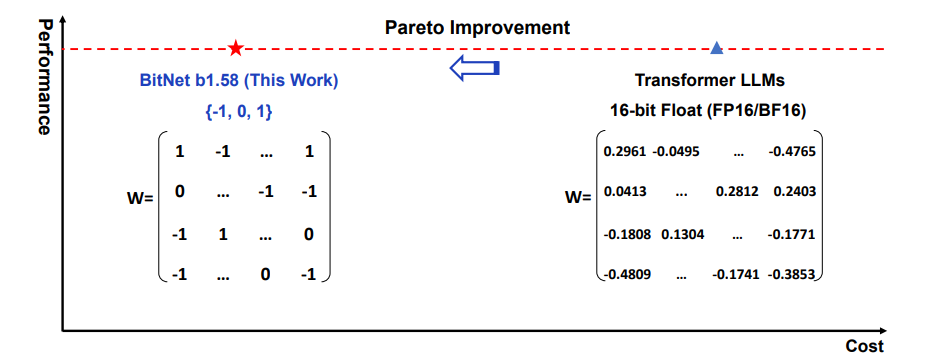
이번에 나온 BitNet b1.58[9]은 1비트가 아니라 1.58비트인데요, 왜 1.58 비트일까요? 일단 1비트부터 알아보면 2개의 경우의 수 (0, 1)을 가집니다. 그리고 2비트는 4개의 경우의 수(00, 01, 10, 11)를 가지죠. 근데 Bitnet b1.58은 3개의 경우의 수(-1, 0, 1)을 가집니다. 1비트와 2비트 사이는 몇 비트라고 표현해야 맞을 까요? 비트는 2진수 이기 때문에 간단하게 log를 적용해서 log_2(3) = 1.5849…의 값을 가지기 때문에 1.58bit라고 표현을 합니다.
1.58 bit
이게 왜 중요한가요?
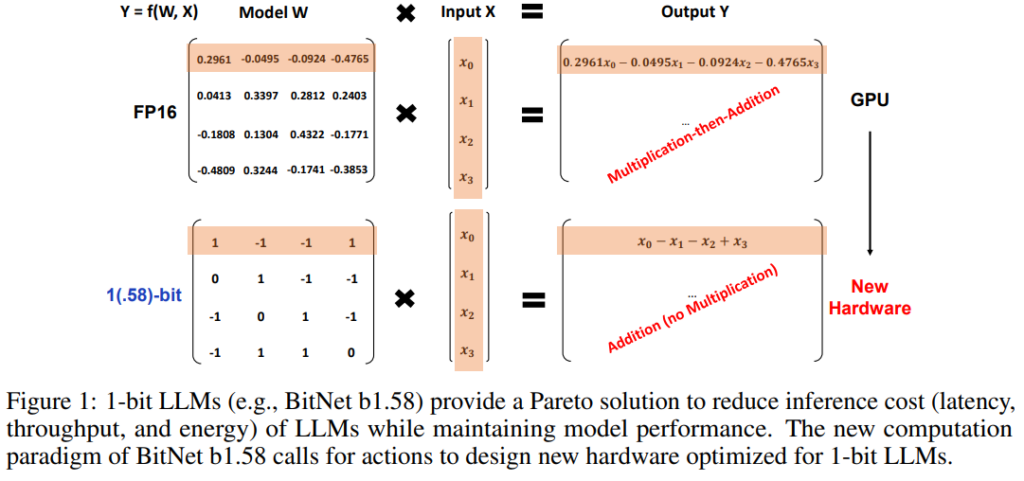
1비트 구조가 갖는 가장 큰 의미는 더 이상 행렬 곱셈이 필요하지 않다는 것입니다. 즉 새로운 계산 패러다임을 제시했고, 행렬 곱셈이 필요하지 않기 때문에 1비트 LLM에 최적화된 새로운 하드웨어를 만들 수 있게 됩니다. 또한 에너지 소비량, 메모리 소비량, 처리량, 지연 시간 측면에서 FP16 LLM에 비해 훨씬 더 효율적입니다.
no need multiplication only addition
그럼 성능이 떨어지지 않나요?
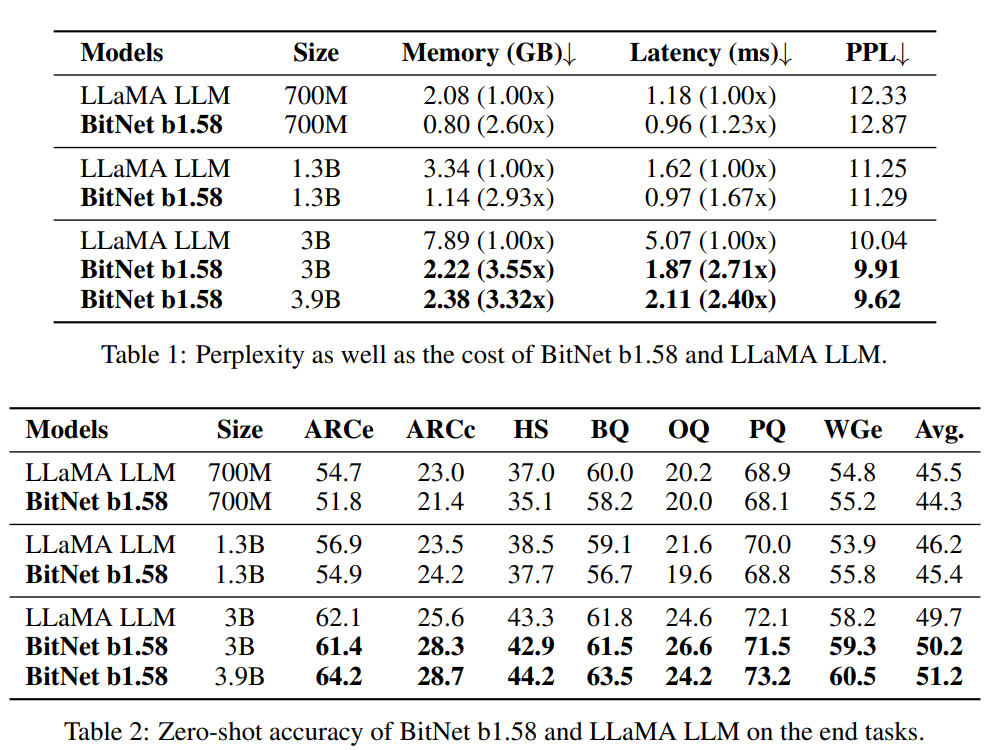
이 표에 따르면 BitNet b1.58은 모델 크기가 3B인 경우에 LLaMA 보다 2.71배 더 빠르고 3.55배 더 적은 GPU 메모리를 사용합니다. 특히 모델 크기가 3.9B인 경우 BitNet b1.58은 2.4배 빠르고 메모리를 3.32배 적게 사용하지만 LLaMA 3B보다 훨씬 더 나은 성능을 보입니다.
Perplexity and accuracy of BitNet b1.58
앞으로 어떤 점을 기대할 수 있을까요?
Mixture-of-Experts (MoE)[10]은 Mixtral(Mistral7B * 8)[11]에서도 입증이 됐듯이 언어모델의 성능 향상에 많은 도움을 줬습니다. 하지만 여러개의 모델을 사용하기 때문에 모델의 크기가 크다는 단점은 여전히 존재합니다. 1.58bit MoE가 나온다면 MoE의 장점과 언어모델의 성능은 유지하면서 경량화된 좋은 언어모델이 나올 것 같습니다. 또한 메모리를 적게 차지하기 때문에 자체적으로 긴 context를 입력으로 처리할 수 있게 되죠.
앞서 설명한 것 처럼 1bit LLM을 위한 새로운 하드웨어가 나오는 것을 기대해볼 수도 있는데요, 최근 Groq에서 보여준 LPU의 성능은 LLM을 위해 설계된 하드웨어의 성능을 제대로 보여줬다고 생각합니다. 이와 통합해서 엣지 디바이스나 모바일에서도 고성능 LLM을 사용할 수 있게 될 것으로 기대됩니다.
Endplan은 유튜브에서 매주 인공지능 트렌드를 업데이트 합니다. 영상에서는 매주 트렌드와, 주목할 논문들을 소개합니다. 구독과 알람설정을 해주시면 빠르게 새로운 정보를 받아보실 수 있습니다.